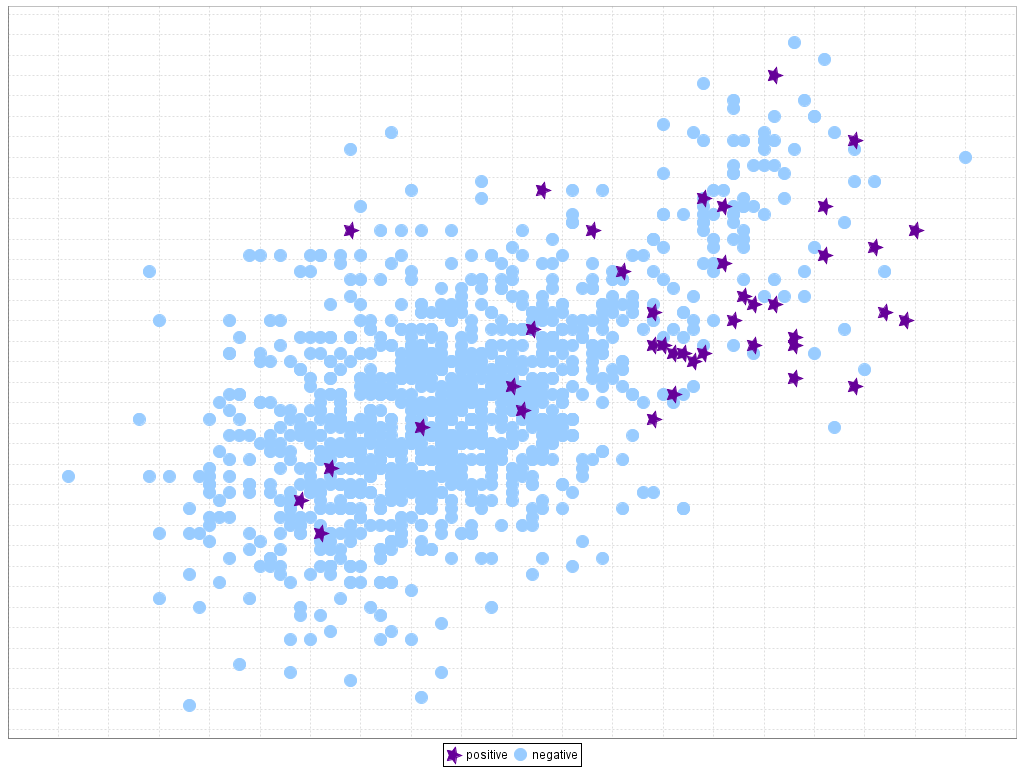
If the Data Scientist is not as naive as we thought, he might analyse the output and observe that the predicted labels are “0” regardless of the input. Over 99.9% of the samples in the dataset won’t represent the rare event, because of this any classifier would yield a extremely high accuracy just by never predicting the event.
In order to achieve meaningful results in a data mining methodology, and especially in classification tasks, it is mandatory to work with a balanced distribution of data that supports equals costs of misclassification (i.e. predict the “wrong” class). At the end, it is essentially all about the amount of points belonging to the minority class (the event occurring) being far smaller than the number of the data points belonging to the majority class (the event not occurring).
How is an imbalance presented in your dataset?
An imbalance can be found in different forms within a dataset:
- Between-class and within-class: As expected in safety related events, it’s expected that there are only few binary classes identifying “bad” occurrences. This imbalance also can be presented within classes in the case that some specific “bad” event is even more rare than the others.
- Intrinsic vs extrinsic: Intrinsic imbalance is due to the nature of the dataset, while extrinsic imbalance is related to time, storage and other factors that limit the dataset or the data analysis. Although in safeclouds.eu we expect to face only intrinsic imbalance, we should not discard the occurrence extrinsic imbalance related problems.
- Relative imbalance vs absolute rarity: Sometimes the minority class may be outnumbered, however it is not necessarily rare, therefore this can be accurately learned with little disturbance. Note that, although the data present imbalance, it is not be something necessarily bad (and could even positive when using certain classifiers). It is very important to determine whether the imbalance is relative or if it is due to absolute rarity.
- Small sample size imbalance: Datasets with high dimensionality and small sample size are quite normal in actual data science problems (face recognition, gene expression, etc…). The dataset size limitations will be the cause problems such as embedded absolute rarity and within-class imbalance, which has been discussed extensively. Limited datasets can also cause specific issues with certain machine learning algorithms such as the failure of generalising inductive rules, difficulty in forming good classification decision boundary over more features but less samples and risk of overfitting.
Conclusion
Class imbalance is a common problem in datasets from multiple well-known domains. It’s a problem than can lead to an erroneous accuracy and incorrect conclusions. Due to the heavy repercussions of this, any skilled Data Scientist should identify and tackle class imbalance. If you want to find out how to tackle these problem using different methodologies such as sampling, cost-effective learning or kernel based algorthims read on to part 2 of this series of posts.