As humans, we rely on our senses to interpret and understand the world around us. Of all our senses, vision particularly stands out. Throughout our history, vision has evolved to become, compared to other species, our dominant sense. On a day-to-day basis, we rely on our vision as our basic source of information. We use it to drive to work, design products, in marketing campaigns, and, as one specific example, pilots use vision to fly and air traffic controllers to ensure safety. In data science, vision (or visualization) is not only important for analyzing data but also for transmitting information and insights. Developments in machine learning and AI make it only a matter of time before scientists, a la Frankenstein, give computers the gift of vision.
What is computer vision (CV)?
CV can be defined as enabling a computer to see, identify, process and extract useful insights from an image. The final goal is to emulate human vision as a form of gathering information. Today, CV is still a flourishing field that, nevertheless, can already provide powerful techniques such as image classification, object detection and tracking or segmentation with a considerable level of accuracy.
How does computer vision work?
How does our brain work? If our goal is to emulate human vision, CV should be achieved in a manner similar to how our brain enables vision. Of course, we do not yet fully understand how our brain works.
How do we achieve it? A computer sees an image as series of pixels with it transforms to and array. The image below shows a simplified example of the process.
In this example, each pixel is represented by a number from 0-255 (RGB color code). For a 12×16 image size, we end up with an array of 12 x 16 8-bit integer values. If instead of black and white, the image was in full color for each pixel, we would have three values. Then the output array would be 12 x 16 x 3. Some computational problems can start rising from this. A normal sized image can use up an approximate of 2.4 MB of storage. From a Deep Learning perspective, this poses a problem as these models tend to need a vast number of examples for training. This is why training deep learning models for CV requires considerable computing power and evolves at a slower pace in the field.
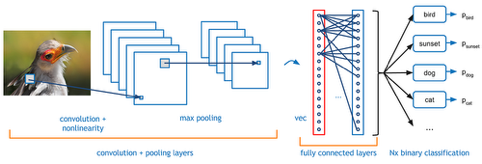
Convolutional Neural Networks (CNNs)
A great variety of algorithms exist but CNNs (and its current evolutions and variants such as ResNet) have been especially relevant to the progress made in CV. CNNs work basically as normal Neural Networks with the exception of additional pre-processing for feature extraction biologically inspired in the visual cortex. Most of its power relies in these previous steps that optimize the input that is then fed to the final fully connected neural layers.
As it can be seen in the image above, a CNN has 3 main distinct operations (prior to the neural network):
1. Convolution
It gives the algorithm its distinctive name and also is used to extract features from the input image. Using a filter, the original matrix is modified normally into a smaller matrix. Although some of the features may be lost in the process, the main and unique features needed are preserved. The output array is usually referred to as Feature Map. To prevent the loss of important information, many feature maps can be created with different filters. The feature map of each filter has the ability to extract the position of specific features present in the input image. This layered approach has limitations that can be overcome by adding shortcut connections between layers as proposed in ResNet.
2.ReLu (Rectified Linear Unit)
This operation takes all negative valued pixels in the feature map and replaces them with zero. Convolution is a linear process and therefore, we could commit the error of processing images as linear problems – which they are not. ReLu is simply used to input non-linearity back to the process.
3. Max Pooling
The feature maps are scanned, by a fixed set of pixels, and the largest value from each window scanned is taken. This operation reduces the dimension of the feature maps making not only computation easier but also making the algorithm more robust to small perturbations and changes in the image.
Aviation and computer vision
CV is opening a whole new world of opportunities. Big companies such as Google or Facebook are heavily investing in its possibilities. In the aviation industry, which is a very regulated sector driven by the compliance with high safety and security standards, CV is making a timid entrance with enormous potential, just as other deep learning applications. Maintenance seems the main focus today of new data science related applications such as Predictive Maintenance. One of the most promising use case applications of CV is in external inspections. When enduring lightning, birds or severe turbulence, an aircraft must be submitted for a thorough external examination. This can ground the aircraft for days, heavily costing the airline. The use of CV could help reduce the average inspection time and even improve accuracy. Research is being made in this area and some airlines are already looking to implement this solution. Other possible uses that are being considered are aircraft tracking at airports or Foreign Object Debris (FOD) detection. However, important errors have been reported by simply adding minor distortions to images, making it possible to mistake a stop sign for a toaster. These seemingly obvious errors reflect how the state-of-the-art of CV is far from human cognitive processes.
To conclude, giving a computer the ability to see is a very complex task, perhaps indicated by our own lack of understanding of human vision. Nevertheless, impressive advances have been made in this field. This provides us the challenging opportunity of fusing the power of present day computational capabilities with new venues of AI and Cognitive models. Quoting Geoffrey Hinton, widely revered as the “godfather of deep learning”: “If we really want to get to general artificial intelligence, then we have to do something more complicated or something else entirely… It’s not just about stacking layers and then backpropagating some error gradient recursively”.