
Semi-Supervised learning in aviation
Eugenio Neira
Machine learning allows us to automatically learn hidden patterns in the data. Traditionally, machine learning models are classified as supervised learning, unsupervised learning and reinforcement learning. In this article, we focus on the synergy between the first two paradigms:
- Supervised learning. The objective is to find functions that establish a correspondence between inputs and target outputs when given example pairs of input-output. Hence, the knowledge is based on the set of examples being correctly labeled—this kind of data is generally more scarce or involves a higher cost of collection. Main use cases of supervised learning are classification and regression.
- Unsupervised learning. In contrast, there is no defined target variable. The aim is to increase the structural knowledge of the available data. Data is not labeled, and thus, we generally have greater availability and lower cost of collection. Some examples of unsupervised learning are grouping of data according to similarity, namely, clustering, dimensionality reduction or topological learning.
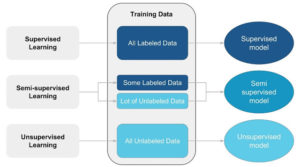
Image source: https://business.blogthinkbig.com/semi-supervised-learning-the-great-unknown/
In aviation, there are plenty of problems where we have a large amount of unlabeled data, but a smaller set of supervised data. For example, most aircrafts have a Flight Data Monitoring (FDM) system that records data from multiple aircraft’s systems with a resolution of up to 8 samples per second. However, only a small sample of the flights is analyzed and correctly labeled with events that could imply a safety risk.
Why not use a combination of supervised and unsupervised learning to make the most of the data we have available, either labeled and unlabeled?
This approach, widely followed in ML community, is known as semi-supervised learning. The strategy is to apply unsupervised techniques to extract patterns and useful features representation from both labeled and unlabeled data. These learned characteristics are then applied to train supervised models in order to boost performance and results.
In 2009, when ML was not yet so popular, researchers from the University of Texas published a paper on cause identification from aviation safety reports, in which they pointed out the lack of annotated reports versus the large amount of unlabeled data. To overcome this problem, they devised a simple semi-supervised bootstrapping algorithm to artificially increase the amount of annotated data, balance the skewness between classes, and ultimately improve classification results of minority causes.
Since then, progress in the field of Natural Language Processing has been enormous. One of the main keys to progress has been the representation of words or phrases as vectors, also known as word embeddings. Through unsupervised techniques, such as neural networks or dimensionality reduction of word co-occurrence matrices, the semantic relationship between words is captured. These representations can be used to improve results in supervised learning applications such as machine translation, sentiment analysis or text classification.
Another illustrative example is the application of semi-supervised learning in computer vision tasks. Let’s say that we aim to correctly classify the aircraft type of an image. Again, we assume that there are plenty of unlabeled pictures of aircrafts, but only a small set of photos with the classification labels. First, we could learn a representative structure and features with increasing levels of abstraction (i.e. texture, edges, boundaries, volumes, simple objects) from all available images, whether labeled or not. For instance, we could apply convolutional auto-encoders to decompose and reconstruct the inputs, and learn these new representations. Then, the knowledge learned could be transferred and used to feed a supervised classification model on the labeled examples. The explanation of these models is beyond the scope of this post; however, it is worth highlighting that we can gain valuable insights from unlabeled images of aircrafts and use these insights to enhance the solution to the classification problem.
The research developed by our colleagues Dario, Antonio, Samuel and Pablo to detect unknown hazards during the aerial approach phase also follows a very interesting semi-supervised strategy. In this use case, they apply auto-encoders to detect anomalies in the approach phase. A LSTM encoder-decoder architecture is trained with inputs from FDM data of normal approaches, and, as a result, anomalous approaches or unknown safety risks are labeled based on the reconstruction error. We strongly encourage you to read it.
In short, the aviation industry has numerous challenges ahead that machine learning is helping to solve: from improving operational safety, enhancing airport services or scaling air traffic management. Although a priori many of these problems involve supervised tasks, making the most from the available data, learning the structure and patterns from unlabeled data can help lead to success when applying machine learning solutions.
——
References
Semi-Supervised Cause Identification from Aviation Safety Reports:
https://www.aclweb.org/anthology/P09-1095.pdf
Flight Data Monitoring (FDM) Unknown Hazards detection during Approach Phase using Clustering Techniques and AutoEncoders
https://www.sesarju.eu/sites/default/files/documents/sid/2019/papers/SIDs_2019_paper_71.pdf


