
Moving to a data-centric approach to solve Machine Learning problems in aviation
Antonio Fernandez
Recently, the debate has grown between using model-centric and data-centric approaches when solving ML problems. Data scientists can sometimes focus too much on refining their models: tuning hyper-parameters, for example, or working to optimize accuracy. However, this route doesn’t always entail improvements to model performance. In most cases, curating the dataset leads to greater improvements in the model. This is also known as a shift from a model-centric approach to a data-centric approach in the machine learning lifecycle.
In order to achieve a good AI system solution, we have two components: the code, which basically refers to the algorithm or model, and the data. But what is the right balance to achieve success? In most industries, open datasets released by global authorities, such as EUROCONTROL or IATA in our case, provide data that is more or less well-cleaned and consistent. For ML case studies built over these datasets, it’s common to follow model-centric approach, which means that solution improvement mostly involves tuning the code. But as argued by Andrew Ng in his latest livestream, by investing in data preparation, data scientists can expect to improve the quality of a noisy dataset in a manner as effective as tripling the volume of the same dataset.
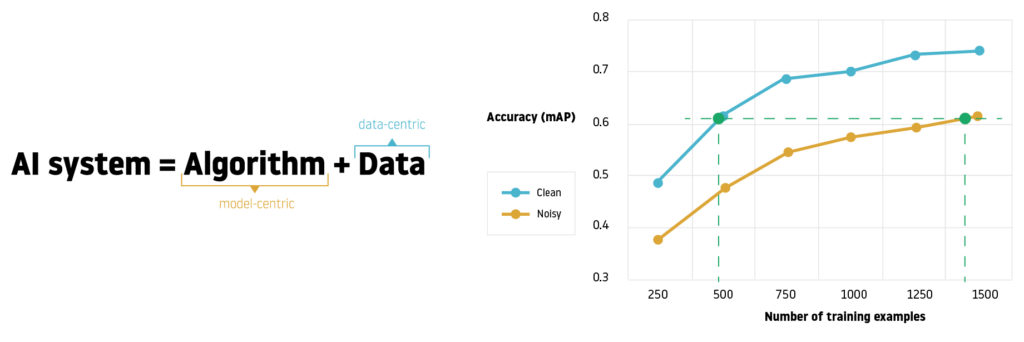
Model-centric vs Data-centric approach.
The first focuses on improving the code; the second invests on improving the data quality.
What are the differences between model-centric and data-centric?
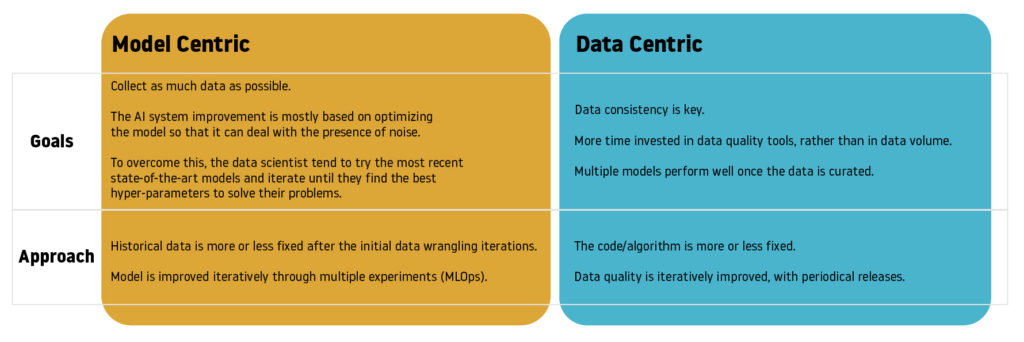
Plenty of model-centric tools exist in order to track machine learning experiments, compare improvements across independent iterations and store all the metadata from the executions. Model-centric tools play an important role in MLOps, whose goal is to produce better ML models faster by being data-driven and applying DevOps practices to ML systems. Data-centric tools (open source or not), on the other hand, have been increasingly overlooked, though they allow us to review datasets, tag potential outliers and lead to ETL pipeline corrections or discarded observations for a particular case study. The data science community is calling for even more tools that enable data curation and preserve the trustworthiness of labels in a simple, reproducible and accessible way.
In almost every research field, including aviation, the quality of data needs to improve; nowadays, tools or frameworks that focus on assessing data quality and track, store and index feedback collected from large scale curation processes are growing in demand. Specific to aviation, the predominant source of data is the time series. Surveillance radar, flight data monitoring, regulations…almost everything consists of a sequence of events or measurements that conform to a certain operation. But how can we curate these kind of datasets? Is there a standardized tool that makes it easier to review the series and note outliers or inconsistent observations? There is no clear answer.
Although it’s important to have a tool or framework that enables this curation process, we also need the infrastructure to process all the feedback collected and to index and retrieve it from particular applications, such as predictive models. In the case of labels revision, experts might differ on how to verify true values depending on their experience, knowledge, daily procedures, letters of agreement, etc. These results must be ranked and served in a simple way so that machine learning models can take advantage of them. For those classes where labelers disagree, data scientists must revise the labeling pipeline until they become consistent.
Imagine a case study using surveillance data (ADS-B) as the main data source. Trajectories often present outliers, errors in sensors, discontinuities or shadow regions that directly affect to labels; however, in most of the observations, the data quality is more than acceptable, even without deep data cleaning. For a constrained dataset containing around 10.000 flights, some (let’s say 15%) will add some noise to the model due to wrong observations. If, for example, we wanted to label maneuvres by aircraft, this label would probably be influenced by the low quality of observations, with fake right and/or left turns caused by errors in the track, or jumps in the trajectory produced by location deviations that were propagated along the points after interpolating the time series. Most of the time, it’s difficult to detect this kind of issue in advance, and data curation tools that enable data visualization (e.g. plot trajectories on a map or detected maneuvers) can be very helpful in mitigating the impact of noise in predictive models performance.


