Most people not familiar with Data Engineering concepts assume volume as the main (or only) reason for data to be Big. In general, volume refers to the gross amount of data; or, simply the size. However, a data set of a few petabytes of data might not be considered Big Data. Why? Because it does not suit the specific Machine Learning applications.
Two more characteristics are needed for a dataset to be considered Big Data. The first is variety, which is related to the number of types of data in your data set. I have seen some people believe that a large, or high volume, dataset would be more varied because it is more likely to contain different combinations of data, or. examples. That is simply a misconception. For instance, if the main driver of the system is not part of your data, it doesn’t matter how many samples you have.
The second characteristic to Big Data is velocity. In statistics, there is the concept of stationarity, which is both important and difficult to apply in practice based on past or future data. A time series is said to be stationary if all its statistical properties are constant in time, which includes past and future points in the series. There are stationarity tests, but they can be applied only to known data, or past data. There is no way to know if a system would be stationary in the future, so the assumption is that will not be. Assuming non-stationarity means that the ML model needs to be continually reevaluated to adapt to the new statistical properties.
How to increase the accuracy of your ML models
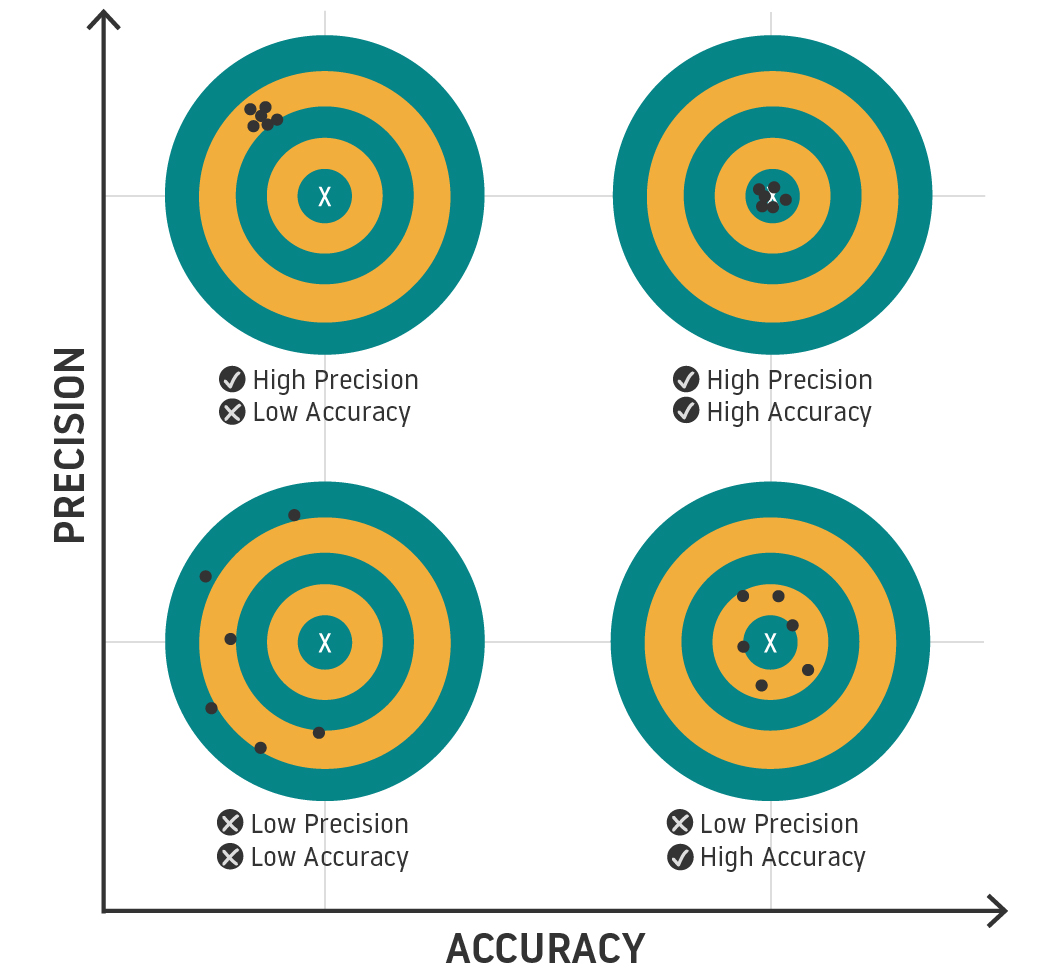
Assuming your model is mathematically sound, its high volume will yield increased precision. Intuitively, more data of the same type will make your model more confident of its results with less dispersion. On the other hand, more variety increases accuracy, and the more types of data in your data set, the higher the chances any type (or combination) contains more elements that actually drive your estimations.
Ideally, Machine Learning models should have both, precision and accuracy. However, in socio-technological systems, variety in isolation is not possible. In aviation, there is an increasing need to open up and collaborate. Although most stakeholders recognize the value and the need for collaboration, open platforms that may ensure security and privacy of the data in the aviation sector are still scarce.
Machine Learning in aviation is finally taking off.
On the 30th April 2019 at the Strata Data Conference, London UK, I will be presenting DataBeacon, a Big Data platform for aviation. You are very much welcome to join. Here is the abstract:
DataBeacon is a multi-sided data platform (MSP) for aviation data. It matches among aviation stakeholders, research institutions and industry interest and facilitate the exchange of information, thereby enabling value creation for all participants.
Different data owners and consumers of analytic services interact through DataBeacon and, using secure common exploitation of data, improve their performance among various aspects of their business.
Private environments hold the data but are not accessible by applications or analysts directly. Instead, data is consumed by the Secure Data Fusion (SDF) technology. One of the major advantages of the SDF technology is being able to merge private data from different sources using secure cryptographic techniques. This enriches each isolated data set by combining multiple sources of data, while also respecting the privacy of the data owners.
DataBeacon complete analytics environment consists of a high availability, on-demand cloud computing architecture for analysis and applications. After secure login, a complete data science development environment is launched, which includes popular data science toolsets. Secure access to Notebooks allows the analysts to work remotely with the protected data – no data leaves the cloud.
Feel free to drop me an email if you are interested in discussing ML in aviation further or even want to join us in DataBeacon.