
Leveraging Lakehouse Architectures to store Aviation Datasets
Antonio Fernandez
Dealing with huge datasets can sometimes be quite complicated, especially when filtering specific data needed to carry out analytics. For instance, if you are working on a predictive model particularized for a certain airport or aircraft type, the process of filtering ADS-B trajectories or FDM data reading from your data lake might become very time consuming. Data management is as important as data analysis or machine learning model training, since the way data is structured might indirectly worsen data loading and processing times, or increase cleaning code complexity, among other aspects.
In this post, we are going to discuss the emerging lakehouse architecture (first introduced by Databricks) and how it might improve not only the accessibility to the data, but also speed up its processing. In particular, it takes advantage of Spark and saves costs in comparison with typical data architectures, such as warehouses or hybrid combinations of data lakes and warehouses. Data lakehouses, or simply lakehouses, emerged as a combination of data lakes and data warehouses powered by Databricks. This new paradigm has become very popular recently, and tries to overcome the limitations of its predecessors. Back in the past, data warehouses were the cornerstone of data management architectures, being able to handle larger data sizes. However, they were tied to structured data, and companies started to collect other types of data (unstructured, semi-structured, etc.), being more aligned with the 3 Vs big data paradigm (ref), which probably sounds familiar to you as it’s a must-have slide in almost any big data conference.
About a decade ago, data lakes emerged to overcome larger datasets coming from a variety of sources and presenting different formats (e.g. images, audio, text, videos, etc.). However, these repositories of raw data lack some critical advantages of data warehouses, such as transactions, data quality enforcement or consistency. Companies require flexible, high-performance systems for diverse data applications, including SQL analytics, real-time monitoring, data science, and machine learning. A common approach is to use multiple systems—a data lake, several data warehouses, and other specialized systems—but it introduces complexity and delay as data need to be moved or copied between different systems. In order to address the limitations provided by data lakes, lakehouses arose and implemented similar data structures and data management features as those in data warehouses, but on the kind of low cost storage used for data lakes.
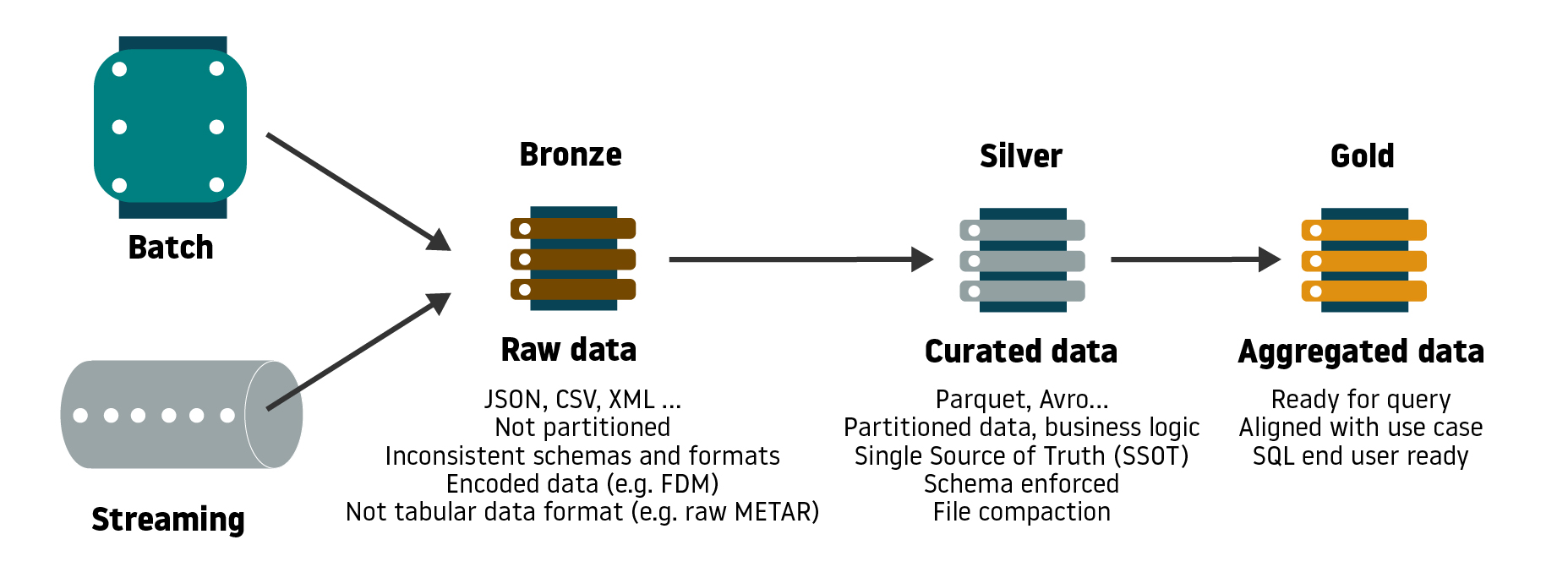
As we already mentioned, Databricks pioneered this technology. They released Delta Lake as an open source table storage layer over the objects stored in our cloud (e.g. S3 or Blob), enabling, among other features, transactions, versioning, and the ability to combine batch and streaming in data lake. The Delta layer mainly solves all the issues data lakes used to have, becoming an extremely powerful tool when implementing streaming data pipelines or consuming machine learning models. Databricks’ Lakehouses follow a design pattern architecture to deliver multiple layers of data quality and curation, presenting a 3-table tier nomenclature:
- Bronze: It stores raw operational data. It’s often the landing zone where the data lake ingests all the input data, coming from batch or streaming sources, and in a variety of formats (e.g. CSV, XML, JSON, etc.)
- Silver: This layer stores clean atomic data and represents the single source of truth enforcing a schema. Here the data is typically partitioned and converted from raw formats to Parquet among other data preparation tasks (file decoding, unit conversion, quality checks). It can also be the main source for machine learning and feature engineering.
- Gold: It stores aggregated data, which involves a lot of data processing. Typically it represents the input layer for data science queries and visualizations or reports.
Let’s process all this knowledge and try to apply some of these concept to the aviation field. As we previously discussed in this blog, time series are probably the predominant dataset in aviation industry. Although most of the sources can be consumed in tabular format, a consistent data architecture must work behind the scenes to select, filter, merge and consume subsets of this data to solve machine learning problems or design dashboards. Let’s provide some examples to better understand the potential of lakehousing in aviation.
Imagine that we are working in a project where radar (e.g. ADS-B) is the main data source. We managed to collect 3 years of data (e.g. JSON format) and store everything in the cloud, for instance using Amazon S3 or Azure Blob Storage services. This would correspond to the Bronze layer, since the schema isn’t enforced, and data might have been ingested in our platform either from an ADS-B stream, batch query against an external system, and/or downloaded outright. In this layer, we could also have additional data sources (e.g. weather, flight plans).
Our next step would be to structure and clean our data lake. Notice that, if we were following a legacy data architecture pattern, we would fall into the pitfall of creating an independent data warehouse to store our data preparation pipeline output, which would enable our data scientists to query our data using SQL, but also increase the system complexity and maintenance. That said, we then create a Silver layer in our data lake and partition our data by date (e.g. year, month and day), saving it using any data science state-of-the-art data formats such as parquet or avro. At this stage, the data is ready to be consumed and queried. But rather than isolating it in a warehouse, in this scenario, we would prefer to use lakehousing and benefit from Delta Lake technology. This will enable warehousing capabilities in the Silver layer, implementing performant and mutable tables in our data lake, and allowing queries to be run using SQL or through Spark directly for ETL development.
Though we have a huge amount of data in our system, we have missed a crucial point: our specific data science interests. Having the Silver layer as our single source of truth, we have complete freedom to carry out almost any data-driven analysis. Below are a couple of examples:
- Data labeling (silver) – We need ADS-B particularized by OD pair (LEMD-LEBL) and aircraft type (e.g. A320), aiming to label maneuvers → We could query our data in Delta Lake using Spark and filter those routes of interest (by origin-destination airports + aircraft type), storing them in a new table to label the maneuvers (also using Spark) looking at the flight trajectory.
- Dashboard (gold) – Extract traffic KPIs by aggregating positions per time and sectors → We could move to Gold layer and aggregate hourly a set of KPIs, such as number of aircraft per sector, hourly entry counts (HEC), occupancy, flights attitude etc. We could visualize these aggregations in a dashboard.
- Machine Learning – Train a model to predict a particular sector KPI (e.g. HEC) → We could use Spark to label our target variable and engineer our features using data saved in the Silver layer, and build a curated training set. Machine learning engineers could use this training set to benchmark several the models (e.g. using MLFlow experiments), tune hyper-parameters and optimize the accuracy.
- Streaming – Prepare real-time features to consume a trained machine learning model → We have a trained model in production and we need to compute the features in streaming. With Delta and Spark Streaming, we can reuse the code developed for batch processing but in streaming, and store new data coming from real-time feed extending our Bronze layer. We can also move to more advanced concepts such as building a Feature Store containing both offline and online features.
In conclusion, the emerging lakehousing paradigm, in combination with Delta Lake, offers a new world of possibilities in data architecture and management. Currently both SMEs and big companies from other industries, such as Apple or Disney+, are adopting data lakehouses as data architecture pattern. At DataBeacon we think that lakehouses can help aviation simplify existing data architecture designs or evolve legacy ones, save cloud costs and enable data scientists from the aviation industry to either better organize their data or consume larger datasets in a scalable and performant way.
References
https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
https://datascience.aero/data-sources-aviation/
https://towardsdatascience.com/the-fundamentals-of-data-warehouse-data-lake-lake-house-ff640851c832


