As we rely on Artificial Intelligence (AI) to handle an increasing number of areas of our lives, the issues of privacy and the fairness of AI algorithms are being discussed more in society. Therefore, I decided to dedicate my following two posts on here to those topics. Today, I delve into the question of algorithmic fairness and algorithmic bias.
What? Algorithms can be… bigots?
When I mention algorithmic bias in this post, I am not referring to bias as the statistical measure commonly used by Machine Learning practitioners, but as a “prejudice against an individual or a group”. Yes, as it turns out, algorithms can be prejudiced. Sort of…
A number of fields and methods within those fields, such as medical diagnosis, human resources and hiring, transportation, etc. already rely on algorithms to deliver automated decision-making. The advantages of artificial intelligence making a decision for us, in addition to saving us time and saving us from decision fatigue, is that algorithmic decision-making can process a much larger quantity of data than a human could and thus could be said to be less subjective than humans.
The reality seems to be slightly different. A number of studies have shown that ML algorithms can too be prone to delivering unfair and biased outputs. Biases in data fed to the algorithms are inevitable, and a well-performing model that is good at picking up statistical patterns in the historical data is also going to be prone to those biases. Furthermore, a prediction model might become inherently prone to committing the same biases as humans as it will propagate them throughout its future decision-making once learnt. However, predictive algorithms we develop should be in accordance with The Treaty on the Functioning of the European Union (TFEU), which prohibits discrimination on grounds of nationality and discourages discrimination on the grounds of sex, racial or ethnic origin, religion or belief, and other protected features.
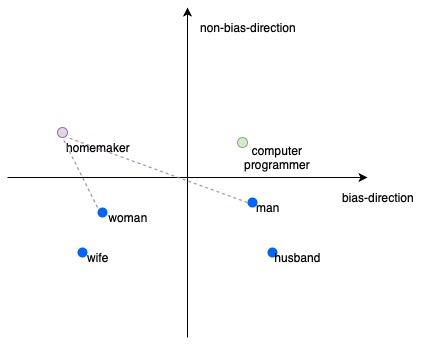
One of the more famous examples of bias learnt by a machine learning algorithm was discovered by Bolukbasi et al. and described in the paper titled Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. Word embeddings are vectors that represent a word or a common phrase and are used in computations performed by algorithms that operate over texts. Bolukbasi et al. have discovered that such embeddings can learn gender biases and thus encapsulate those biases in vectorial representations that are used in subsequent learning algorithms.
The title of the paper was motivated by a particular example of sexism implicitly contained in the embeddings. Following simple algebraic manipulations over vectors of word embeddings, they noticed that the system, when asked to complete the analogy “man is to computer programmer as woman is to x”, gives the answer x=homemaker. Needless to say, most people today would not agree with that analogy. Yet, based on the historical data fed to the algorithm, it was incorporated into the learnt language model.