A problem can always be observed or described differently through various lenses. The point of views of stakeholders, end-users, data scientists and software engineers have implications in the building of a solution, but it’s worth mentioning the differences that exist in the various approaches in order to avoid conflicts and unproductive workflows.
Why understanding key differences between data science and software engineering matters
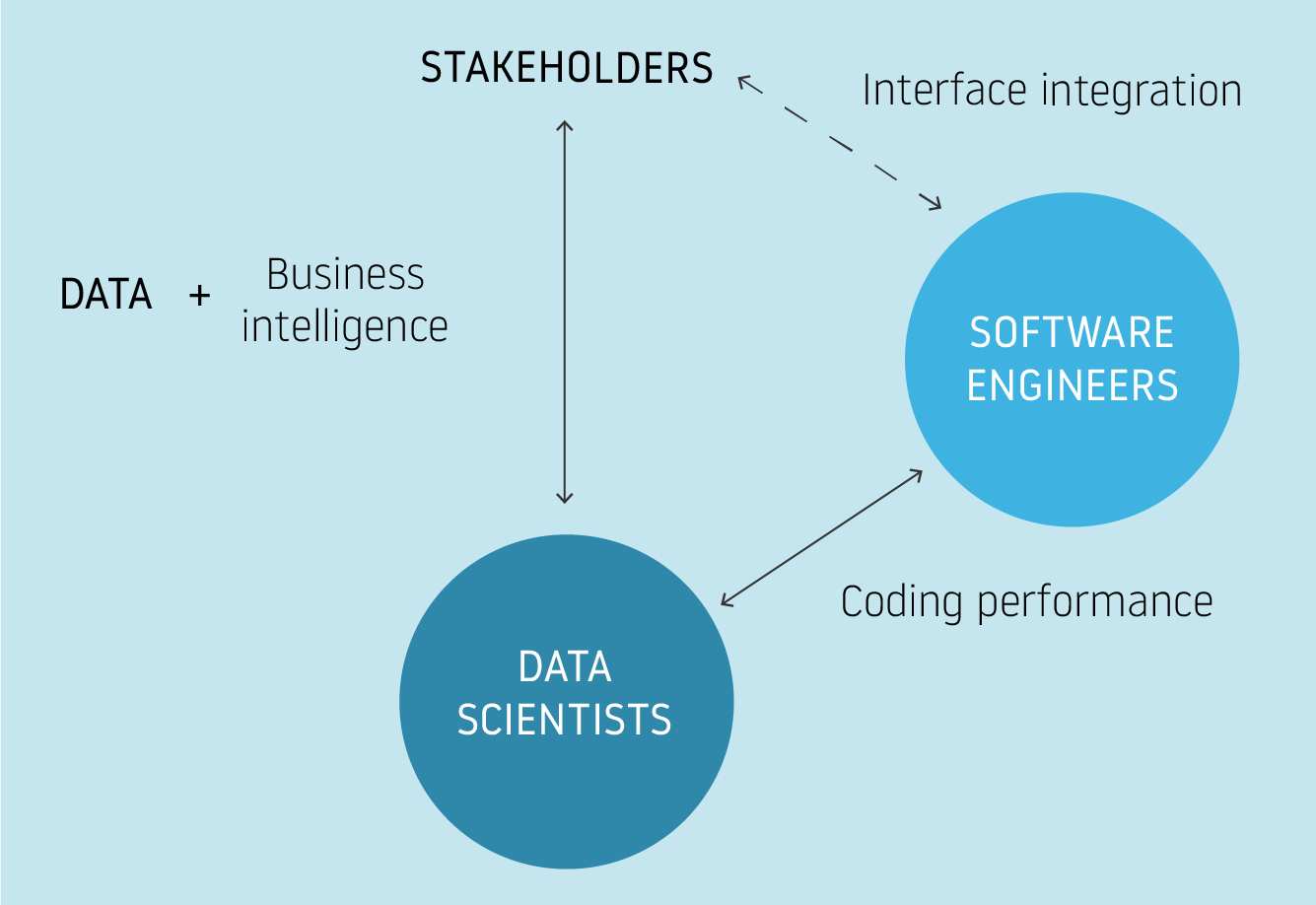
As data science becomes increasingly used and mature within a field (in this case, aviation), it is common to observe collaboration between software/infrastructure engineer and data science teams. While both share coding responsibilities, software development and data science are fundamentally different. Data science is analogous to research: data scientists work closely with stakeholders to answer business questions leveraging their data. Conversely, software engineers seldom engage with stakeholders, but rather collaborate with data science teams to improve and adapt the computing constraints of an existing solution.
Both data scientists and software engineers conduct research, but each focuses on different questions
Safeclouds.eu is a good example of this paradigm. Aviation stakeholders wants to advance their understanding and management of safety issues through an organized and understandable platform. Data science teams are focused on answering specific questions that may output knowledge or a model. It is often an exploratory process to answer stakeholder questions; the research process is not easily predictable nor are the computational requisites always constant, which explains why data science teams typically need more flexibility and agility in the tools and infrastructure they use. It is not surprising to see data scientists finding memory and CPU problems while running computationally intensive experiments on their laptop or a private temporal cloud machine. Data science teams may use solutions to avoid excessive computation times such as quick and simple parallelization or increased memory, although these solutions cannot be used for scale or in the long-term. This being considered, data scientists turn to code most often (Python, Scala, etc.), but this is just a small part of their work as theoretical inputs (statistics, business intelligence, domain knowledge, etc) are significantly more important than coding. That is to say, programming is just the language to express or reflect the research process.
On the other hand, the software engineering teams adapt the proposed infrastructure architecture or the solution software from the data science team. Typically, the proposed solution from the data science team should be validated by the stakeholders before applying it through software engineering. Engineers also perform research, but their investigation focuses on different objectives, as the business problem has already been addressed by the data science team. Software engineers use tracking, monitoring and quality assurance techniques to understand the structure of the specific provided solution (through code) and optimize it to build scalable and high-performance workflows. Their work is not integrated with stakeholders’ input, but rather to the data science output; adapting the architecture to improve the computation performance of the overall delivered solution.