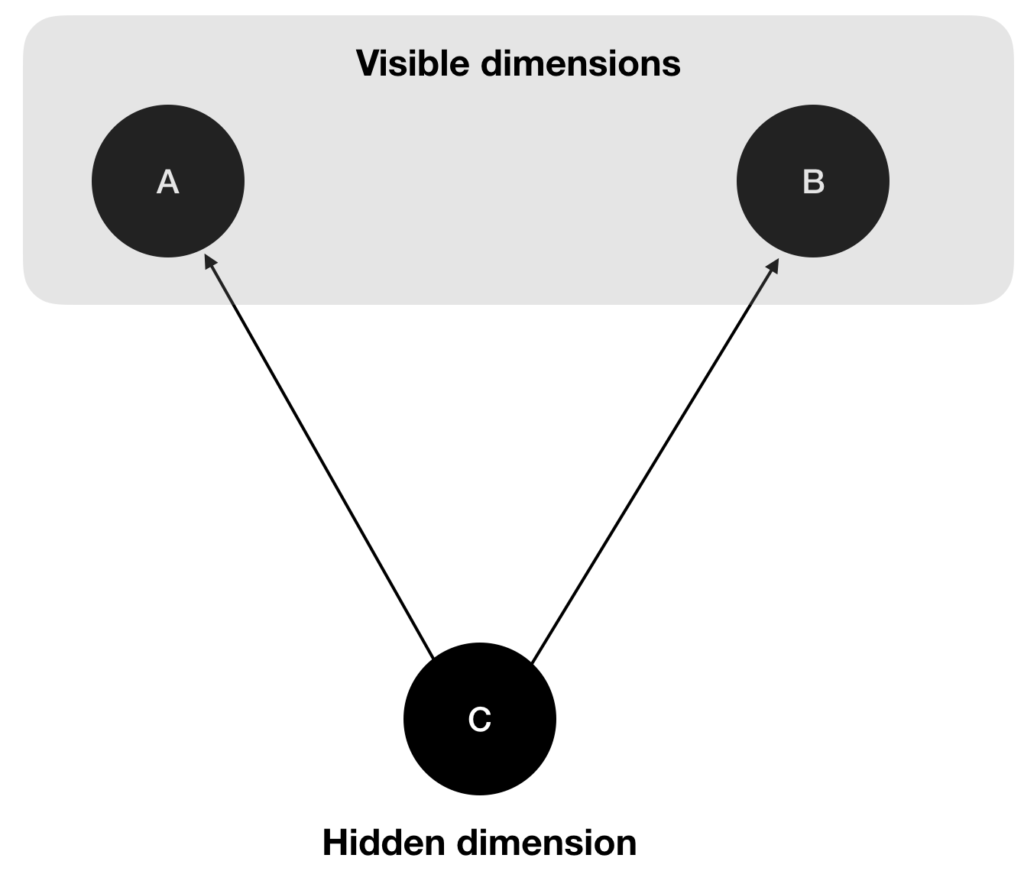
Business and data owners in any complex environment, such as Air Transportation, are keen on the extraction of explanations for events of interest. The term extraction of explanation speaks to how explanations are uncovered within data itself. With the recent explosion computational power and growing amounts of data, the proliferation of Data Mining(1) techniques yield to the natural applications in AT – a clear example can be found in the SafeClouds.eu project where data from various stakeholders (Airlines, ANSPs, etc.) will be used to explain the generation of safety events as unstable approaches.
The general consensus for explanation extraction buttresses on causation definition (Wiener definition to be more exact!), where a specific event that happens prior to the event of interest and helps to predict it must somehow explain its appearance. This has been the base of all predictive/descriptive Machine Learning exercises. First, features are engineered in order to find the best “prior” inputs that helped predict the studied event. After, validation techniques are used to make the research sound and proof. Yet, where no error may be technically found (e.g. data as been successfully separated in training and testing partitions, validation techniques has been applied, no over-fitting is happening, etc.) a fundamental additional step must be included that transforms found predictors into real and useful explanations of an event.